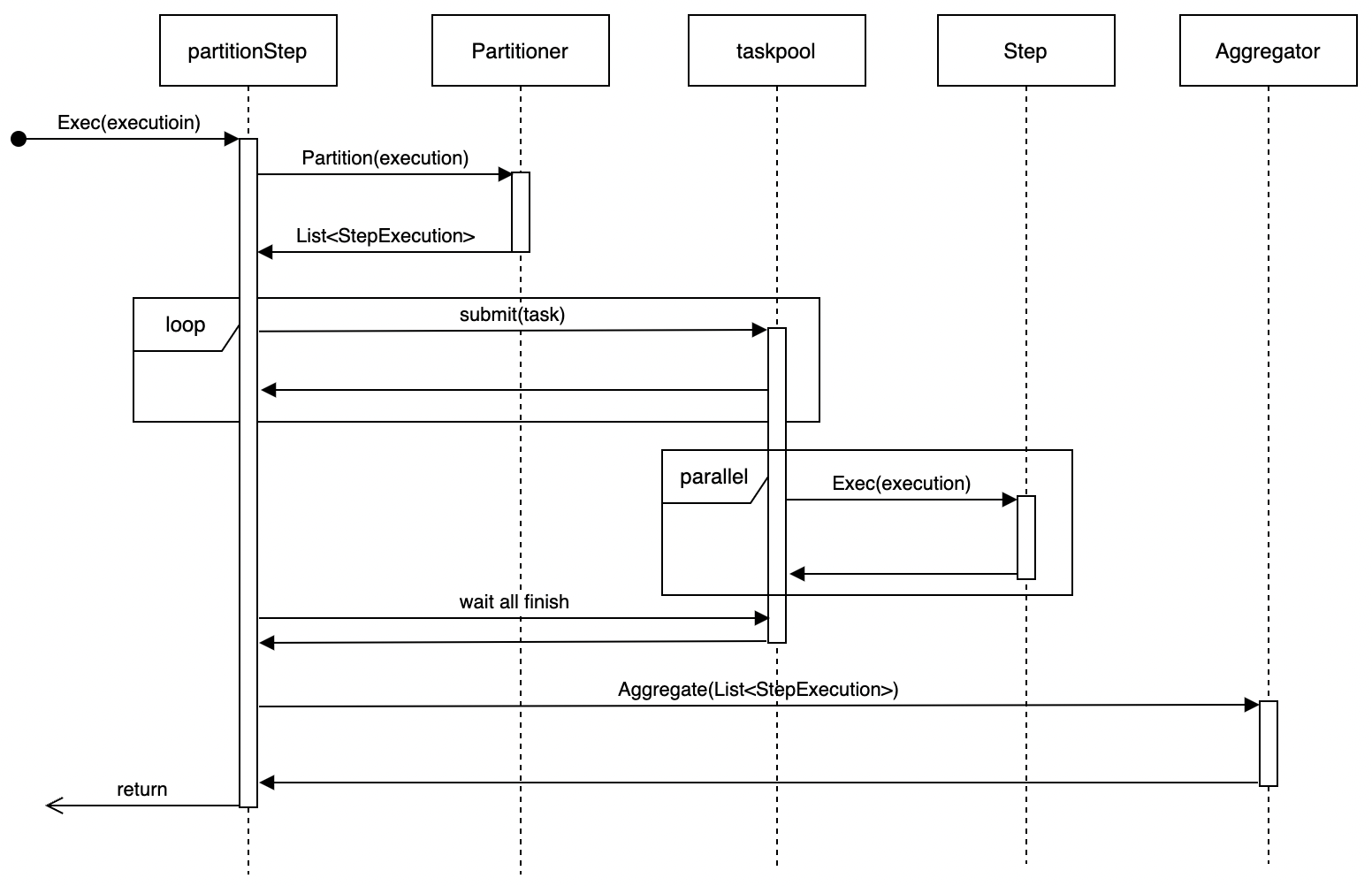
步骤介绍
步骤类型
GoBatch支持三种类型的步骤:
SimpleStep(简单步骤)
- 在单个线程中执行一个任务
- 适用于简单的处理逻辑
- 通过Handler或Task接口实现具体业务逻辑
ChunkStep(分块步骤)
- 以块为单位处理数据
- 实现"读取-处理-写入"模式
- 支持事务管理
- 主要组件:
- ItemReader:数据读取
- ItemProcessor:数据处理
- ItemWriter:数据写入
PartitionStep(分区步骤)
- 支持并行处理
- 将大任务拆分为多个子任务
- 可以聚合子任务的处理结果
- 主要组件:
- Partitioner:任务分区
- Aggregator:结果聚合
编写简单步骤
有多种方法编写简单步骤的逻辑,如下:
// 1. write a function with one of the following signature
func(execution *StepExecution) BatchError
func(execution *StepExecution)
func() error
func()
// 2. implement the Handler interface
type Handler interface {
Handle(execution *StepExecution) BatchError
}
当你使用以上函数定义或接口定义编写好了业务逻辑,则可以通过以下方式构造Step对象:
step1 := gobatch.NewStep("step1").Handler(myfunction).Build()
step2 := gobatch.NewStep("step2").Handler(myHandler).Build()
//or
step1 := gobatch.NewStep("step1", myfunction).Build()
step2 := gobatch.NewStep("step2", myHandler).Build()
编写分块步骤
分块步骤需要实现以下3个接口(其中,只有Reader是必须实现的):
type Reader interface {
//Read each call of Read() will return a data item, if there is no more data, a nil item will be returned.
Read(chunkCtx *ChunkContext) (interface{}, BatchError)
}
type Processor interface {
//Process process an item from reader and return a result item
Process(item interface{}, chunkCtx *ChunkContext) (interface{}, BatchError)
}
type Writer interface {
//Write write items generated by processor in a chunk
Write(items []interface{}, chunkCtx *ChunkContext) BatchError
}
框架还包含一个ItemReader接口,在某些情况下,可以用于代替Reader,其定义如下:
type ItemReader interface {
//ReadKeys read all keys of some kind of data
ReadKeys() ([]interface{}, error)
//ReadItem read value by one key from ReadKeys result
ReadItem(key interface{}) (interface{}, error)
}
为了方便起见,可以通过实现以下接口,在Reader或Writer中执行一些初始化或清理的动作:
type OpenCloser interface {
Open(execution *StepExecution) BatchError
Close(execution *StepExecution) BatchError
}
示例代码可以参考 test/example2
编写分区步骤
分区步骤必须要实现Partitioner接口,该接口用于将整个步骤要处理的数据分成多个分区,每个分区对应一个子步骤,框架会启动多个线程来并行执行多个子步骤。如果需要对子步骤的执行结果进行合并,还需要实现Aggregator接口。这两个接口定义如下:
type Partitioner interface {
//Partition generate sub step executions from specified step execution and partitions count
Partition(execution *StepExecution, partitions uint) ([]*StepExecution, BatchError)
//GetPartitionNames generate sub step names from specified step execution and partitions count
GetPartitionNames(execution *StepExecution, partitions uint) []string
}
type Aggregator interface {
//Aggregate aggregate result from all sub step executions
Aggregate(execution *StepExecution, subExecutions []*StepExecution) BatchError
}
对于分区步骤的子步骤来说,既可以是一个简单步骤(由Handler定义),也可以是一个分块步骤(通过Reader/Processor/Writer定义)。 如果已有了一个包含ItemReader的分块步骤,则可以通过指定分区数量就可以构造分区步骤,如下:
step := gobatch.NewStep("partition_step").Handler(&ChunkHandler{db}).Partitions(10).Build()
这种方式是由GoBatch框架内部基于ItemReader实现了Partitioner。
文件处理
GoBatch提供了内置的文件处理组件,支持:
- 多种文件格式(CSV、TSV等)
- 文件编码设置
- 自动字段映射
- 文件校验
读取文件
我们假定有一个文件的内容如下(其中每行是一条记录,每个字段用'\t'分隔):
trade_1 account_1 cash 1000 normal 2022-02-27 12:12:12
trade_2 account_2 cash 1000 normal 2022-02-27 12:12:12
trade_3 account_3 cash 1000 normal 2022-02-27 12:12:12
……
如果想读取该文件的内容,并将文件中每条记录插入到数据库中的 t_trade 表中,则可以通过以下方式来实现:
type Trade struct {
TradeNo string `order:"0"`
AccountNo string `order:"1"`
Type string `order:"2"`
Amount float64 `order:"3"`
TradeTime time.Time `order:"5"`
Status string `order:"4"`
}
var tradeFile = file.FileObjectModel{
FileStore: &file.LocalFileSystem{},
FileName: "/data/{date,yyyy-MM-dd}/trade.data",
Type: file.TSV,
Encoding: "utf-8",
ItemPrototype: &Trade{},
}
type TradeWriter struct {
db *gorm.DB
}
func (p *TradeWriter) Write(items []interface{}, chunkCtx *gobatch.ChunkContext) gobatch.BatchError {
models := make([]*Trade, len(items))
for i, item := range items {
models[i] = item.(*Trade)
}
e := p.db.Table("t_trade").Create(models).Error
if e != nil {
return gobatch.NewBatchError(gobatch.ErrCodeDbFail, "save trade into db err", e)
}
return nil
}
func buildAndRunJob() {
//...
step := gobatch.NewStep("trade_import").ReadFile(tradeFile).Writer(&TradeWriter{db}).Partitions(10).Build()
//...
job := gobatch.NewJob("my_job").Step(...,step,...).Build()
gobatch.Register(job)
gobatch.Start(context.Background(), job.Name(), "{\"date\":\"20220202\"}")
}
写入文件
再假定我们需要将 t_trade 表中的数据导出为一个csv文件,可以按照以下方式来实现:
type Trade struct {
TradeNo string `order:"0" header:"trade_no"`
AccountNo string `order:"1" header:"account_no"`
Type string `order:"2" header:"type"`
Amount float64 `order:"3" header:"amount"`
TradeTime time.Time `order:"5" header:"trade_time" format:"2006-01-02_15:04:05"`
Status string `order:"4" header:"trade_no"`
}
var tradeFileCsv = file.FileObjectModel{
FileStore: &file.LocalFileSystem{},
FileName: "/data/{date,yyyy-MM-dd}/trade_export.csv",
Type: file.CSV,
Encoding: "utf-8",
ItemPrototype: &Trade{},
}
type TradeReader struct {
db *gorm.DB
}
func (h *TradeReader) ReadKeys() ([]interface{}, error) {
var ids []int64
h.db.Table("t_trade").Select("id").Find(&ids)
var result []interface{}
for _, id := range ids {
result = append(result, id)
}
return result, nil
}
func (h *TradeReader) ReadItem(key interface{}) (interface{}, error) {
id := int64(0)
switch r := key.(type) {
case int64:
id = r
case float64:
id = int64(r)
default:
return nil, fmt.Errorf("key type error, type:%T, value:%v", key, key)
}
trade := &Trade{}
result := h.db.Table("t_trade").Find(trade, "id = ?", id)
if result.Error != nil {
return nil, result.Error
}
return trade, nil
}
func buildAndRunJob() {
//...
step := gobatch.NewStep("trade_export").Reader(&TradeReader{db}).WriteFile(tradeFileCsv).Partitions(10).Build()
//...
}
生命周期监听
步骤执行过程中的各个阶段都可以通过监听器进行干预:
// 步骤监听器
type StepListener interface {
BeforeStep(execution *StepExecution) BatchError
AfterStep(execution *StepExecution) BatchError
}
// 块处理监听器
type ChunkListener interface {
BeforeChunk(context *ChunkContext) BatchError
AfterChunk(context *ChunkContext) BatchError
OnError(context *ChunkContext, err BatchError)
}
// 分区监听器
type PartitionListener interface {
BeforePartition(execution *StepExecution) BatchError
AfterPartition(execution *StepExecution, subExecutions []*StepExecution) BatchError
OnError(execution *StepExecution, err BatchError)
}
执行流程
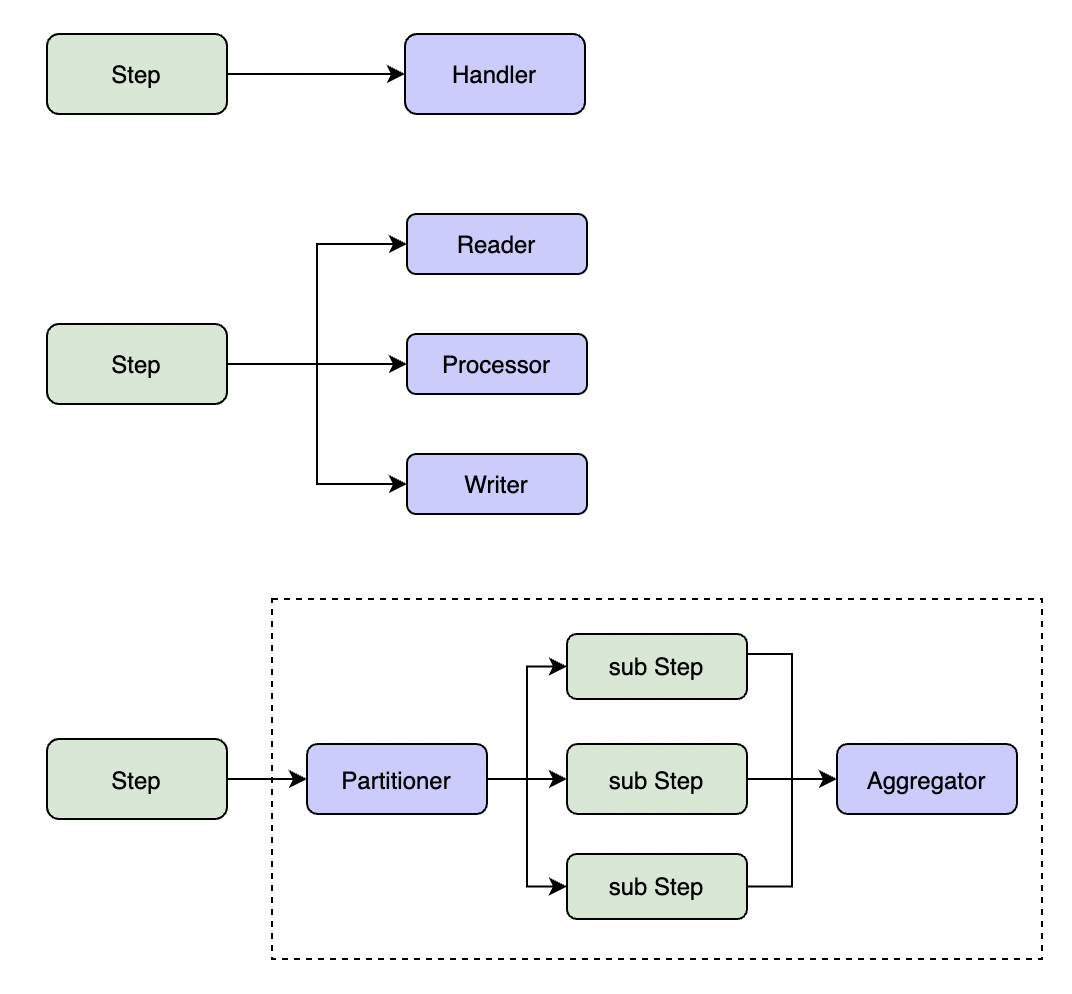
简单步骤执行
简单步骤直接在当前Job线程中执行Handler中的业务逻辑。适合业务逻辑简单的场景。
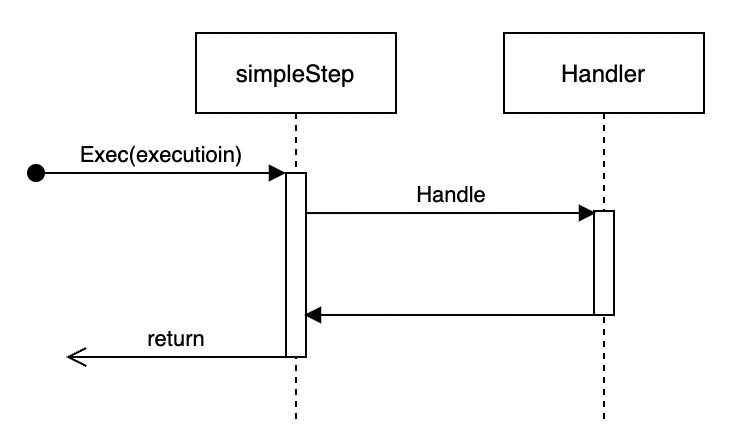
分块处理步骤执行
在单线程中执行以下流程:
- 启动事务
- 读取指定大小的数据块
- 处理数据
- 写入结果
- 提交或回滚事务
- 重复以上步骤直到处理完成
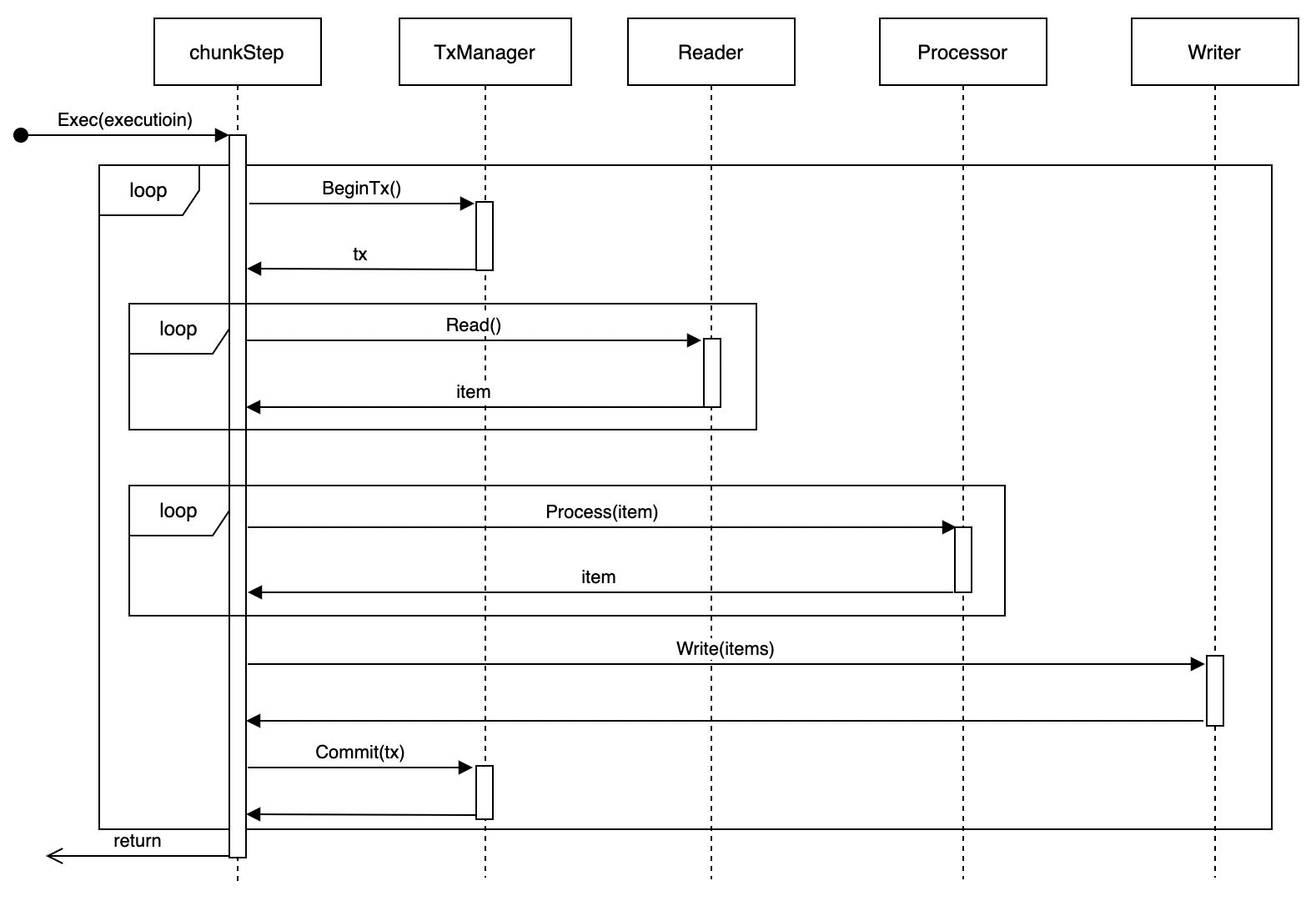
分区步骤执行
- 使用Partitioner进行数据分区
- 为每个分区生成子步骤
- 并行执行子步骤
- 等待所有子步骤完成
- 使用Aggregator汇总结果